Redis基础数据类型及使用场景
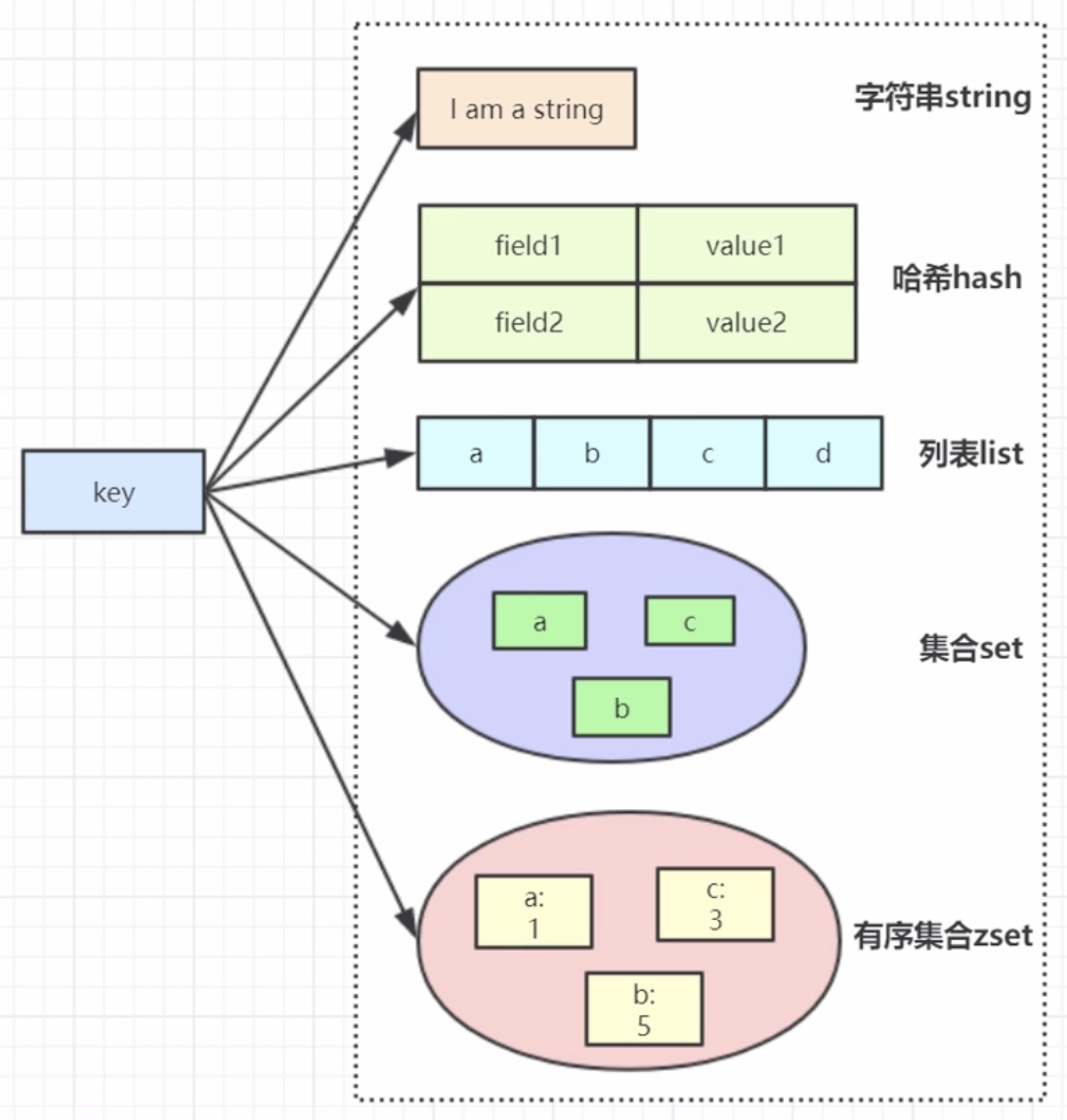
String

缓存功能:String字符串是最常用的数据类型,不仅仅是Redis,各个语言都是最基本类型,因此,利用Redis作为缓存,配合其它数据库作为存储层,利用Redis支持高并发的特点,可以大大加快系统的读写速度、以及降低后端数据库的压力。
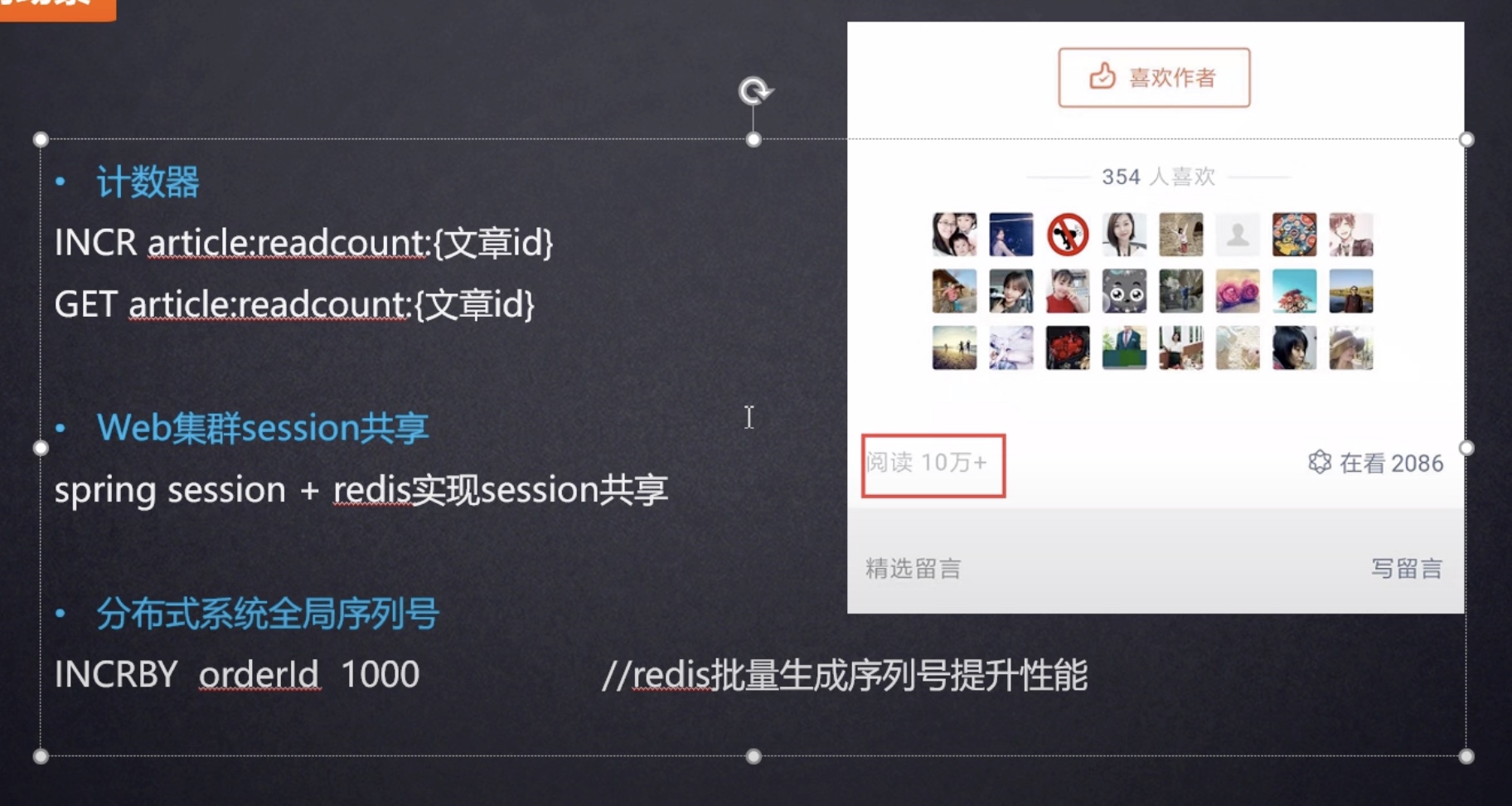
计数器:许多系统都会使用Redis作为系统的实时计数器,可以快速实现计数和查询的功能。而且最终的数据结果可以按照特定的时间落地到数据库或者其它存储介质当中进行永久保存。
共享用户Session:用户重新刷新一次界面,可能需要访问一下数据进行重新登录,或者访问页面缓存Cookie,但是可以利用Redis将用户的Session集中管理,在这种模式只需要保证Redis的高可用,每次用户Session的更新和获取都可以快速完成。大大提高效率。
Hash


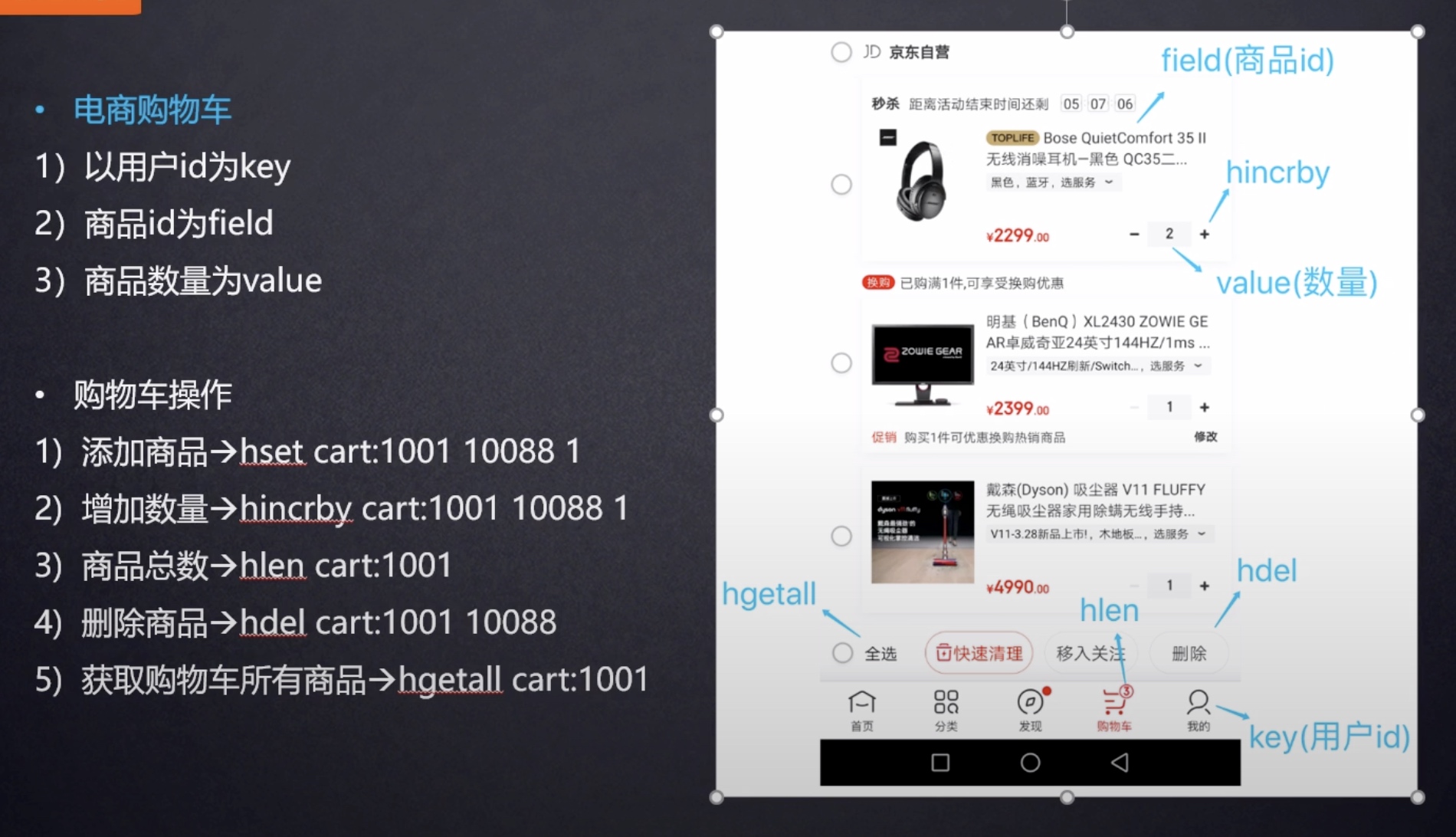
这个是类似 Map 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是这个对象没嵌套其他的对象)给缓存在 Redis 里,然后每次读写缓存的时候,可以就操作 Hash 里的某个字段。
但是这个的场景其实还是多少单一了一些,因为现在很多对象都是比较复杂的,比如你的商品对象可能里面就包含了很多属性,其中也有对象。我自己使用的场景用得不是那么多。

List
List 是有序列表,这个还是可以玩儿出很多花样的。


- 比如可以通过 List 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的东西。
比如可以通过lrange命令,读取某个闭区间内的元素,可以基于 List 实现分页查询,这个是很棒的一个功能,基于 Redis 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就一页一页走。
比如可以搞个简单的消息队列,从 List 头怼进去,从 List 屁股那里弄出来。List本身就是我们在开发过程中比较常用的数据结构了,热点数据更不用说了。
消息队列:Redis的链表结构,可以轻松实现阻塞队列,可以使用左进右出的命令组成来完成队列的设计。比如:数据的生产者可以通过
Lpush命令从左边插入数据,多个数据消费者,可以使用BRpop命令阻塞的“抢”列表尾部的数据。文章列表或者数据分页展示的应用。
比如,我们常用的博客网站的文章列表,当用户量越来越多时,而且每一个用户都有自己的文章列表,而且当文章多时,都需要分页展示,这时可以考虑使用Redis的列表,列表不但有序同时还支持按照范围内获取元素,可以完美解决分页查询功能。大大提高查询效率。
Set
Set 是无序集合,会自动去重的那种。


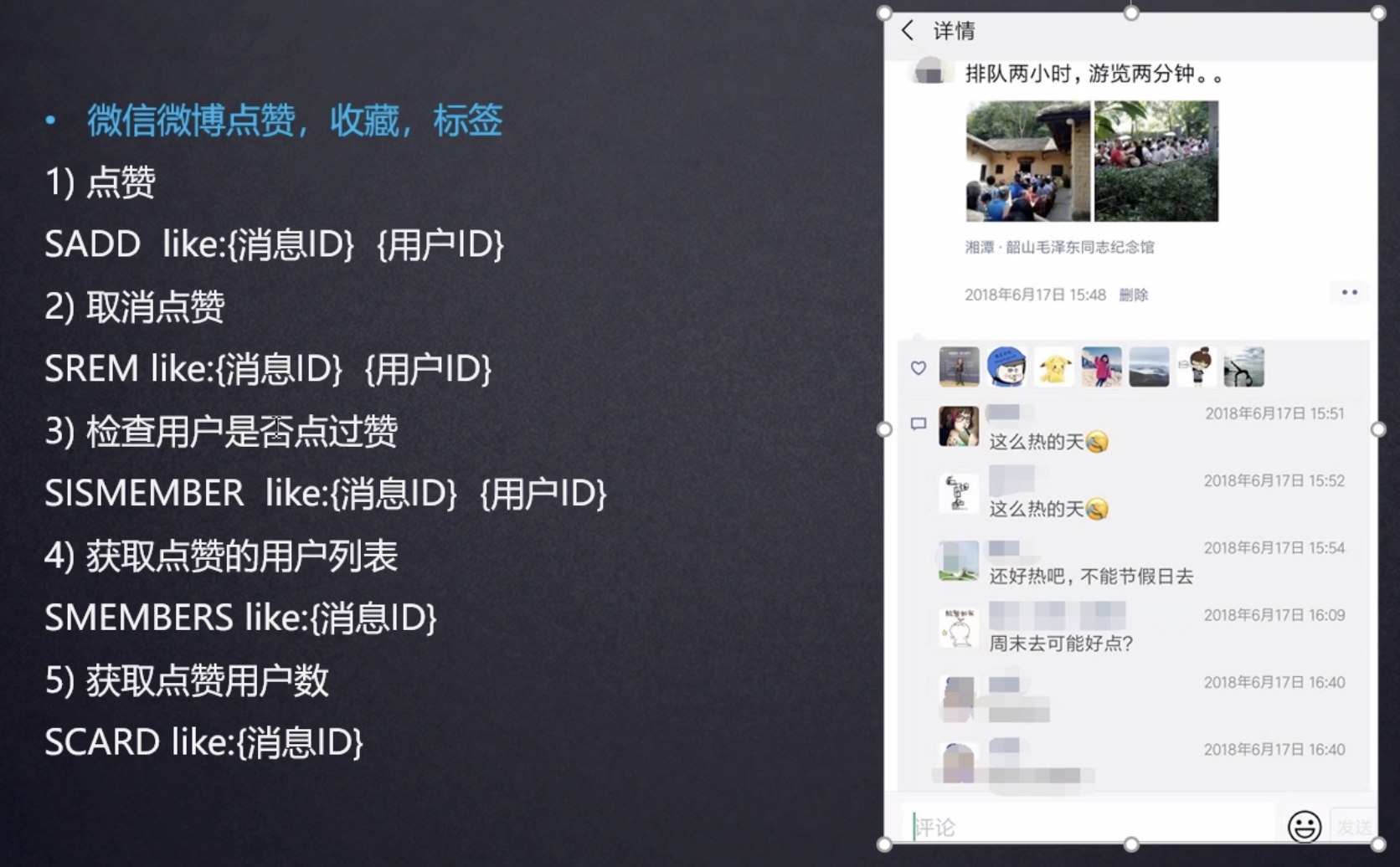
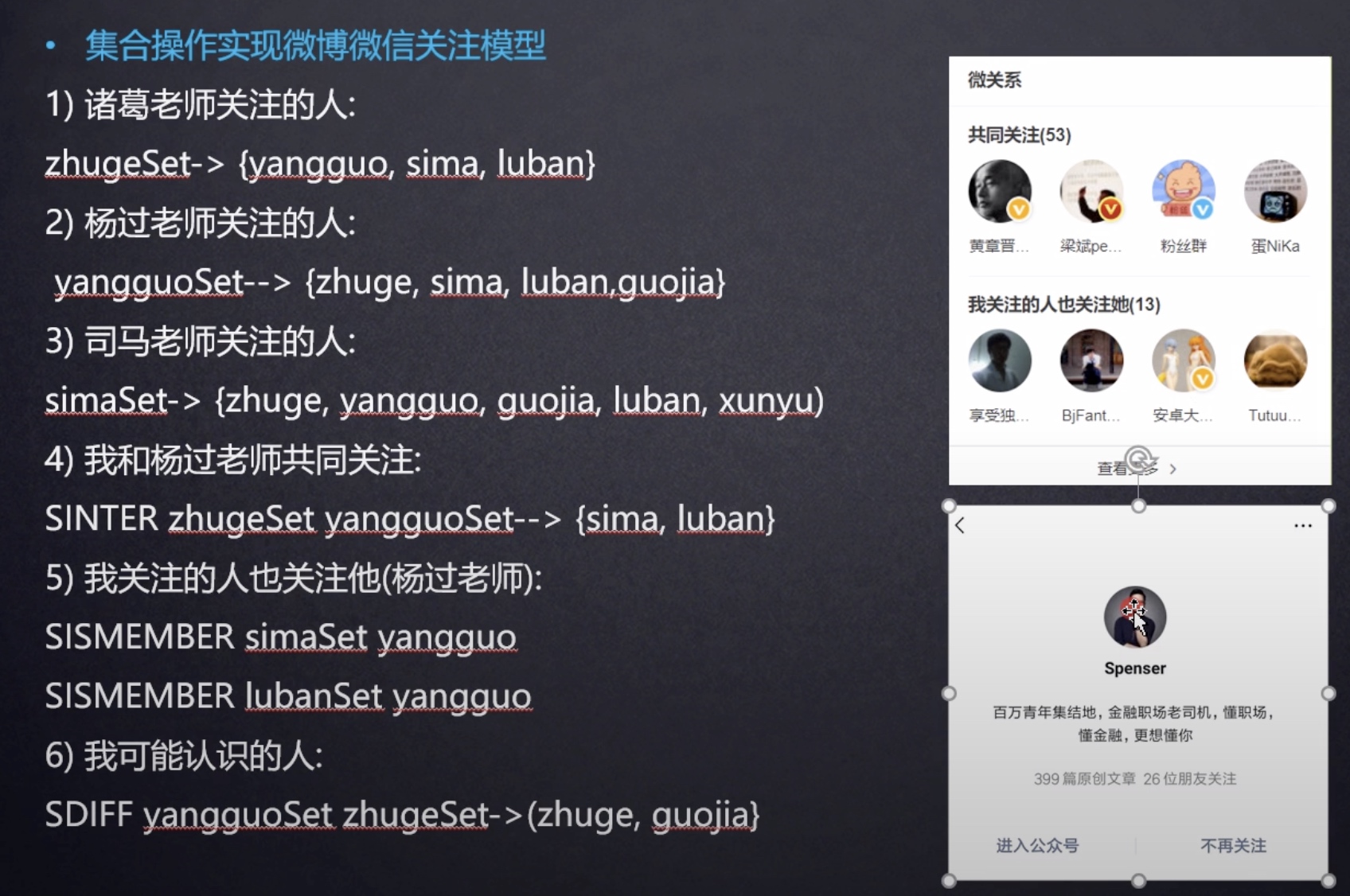
去重: 直接基于 Set 将系统里需要去重的数据扔进去,自动就给去重了,如果你需要对一些数据进行快速的全局去重,你当然也可以基于 JVM 内存里的 HashSet 进行去重,但是如果你的某个系统部署在多台机器上呢?得基于Redis进行全局的 Set 去重。
可以基于 Set 玩 交集、并集、差集 的操作。比如交集吧,我们可以把两个人的好友列表整一个交集,看看俩人的共同好友是谁?对吧。反正这些场景比较多,因为对比很快,操作也简单,两个查询一个Set搞定。
Sorted Set
Sorted set 是排序的 Set,去重并可以排序,写进去的时候给一个分数,自动根据分数排序。
有序集合的使用场景与集合类似,但是set集合不是自动有序的,而Sorted set可以利用分数进行成员间的排序,而且是插入时就排序好。所以当你需要一个有序且不重复的集合列表时,就可以选择Sorted set数据结构作为选择方案。
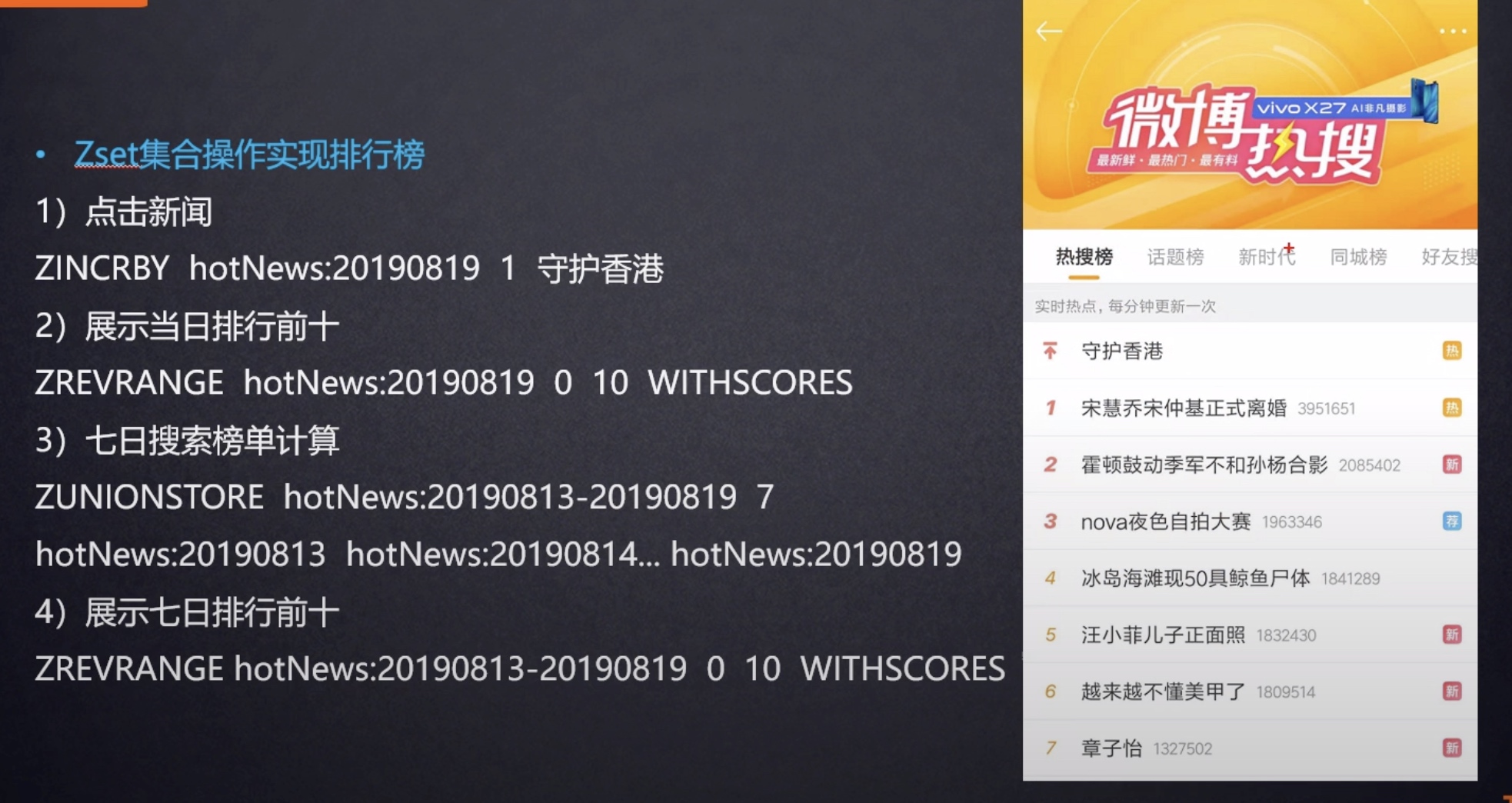
排行榜:有序集合经典使用场景。例如视频网站需要对用户上传的视频做排行榜,榜单维护可能是多方面:按照时间、按照播放量、按照获得的赞数等。
用
Sorted Sets来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
Redis更多应用场景

Redis 和 Memcached 区别
Memcache
先来看看 MC 的特点:
MC 处理请求时使用
多线程异步IO的方式,可以合理利用 CPU 多核的优势,性能非常优秀;MC 功能简单,使用内存存储数据;
MC 的内存结构以及钙化问题;
MC 对缓存的数据可以设置失效期,过期后的数据会被清除;
失效的策略采用延迟失效,就是当再次使用数据时检查是否失效;
当容量存满时,会对缓存中的数据进行剔除,剔除时除了会对过期 key 进行清理,还会按 LRU 策略对数据进行剔除。
另外,使用 MC 有一些限制,这些限制在现在的互联网场景下很致命,成为大家选择Redis、MongoDB的重要原因:
key 不能超过 250 个字节;
value 不能超过 1M 字节;
key 的最大失效时间是 30 天;
只支持 K-V 结构,不提供持久化和主从同步功能。
Redis
简单说一下 Redis 的特点,方便和 Memcache 比较。
与 MC 不同的是,Redis 采用单线程模式处理请求。这样做的原因有 2 个:
一个是因为采用了非阻塞的异步事件处理机制;
另一个是缓存数据都是内存操作 IO 时间不会太长,单线程可以避免线程上下文切换产生的代价。
Redis 支持持久化,所以 Redis 不仅仅可以用作缓存,也可以用作 NoSQL 数据库。
相比 MC,Redis 还有一个非常大的优势,就是除了 K-V 之外,还支持复杂的数据结构,例如 list、set、sorted set、hash 等。
Redis 提供主从同步机制,以及原生支持集群模式,能够提供高可用服务, 在 redis3.x 版本中,便能支持 Cluster 模式; 而 Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据。
性能对比
由于 Redis 只使用单核,而 Memcached 可以使用多核,所以平均每一个核上 Redis 在存储小数据时比 Memcached 性能更高。而在 100k 以上的数据中,Memcached 性能要高于 Redis,虽然 Redis 最近也在存储大数据的性能上进行优化,但是比起 Remcached,还是稍有逊色。
Redis 线程模型
Redis 内部使用 文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以 Redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 Socket,根据 Socket 上的事件来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
- 多个 Socket
- IO 多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个 Socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 Socket,会将 Socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
高级用法
Bitmap
位图是支持按 bit 位来存储信息,可以用来实现 布隆过滤器(BloomFilter);
HyperLogLog
供不精确的去重计数功能,比较适合用来做大规模数据的去重统计,例如统计 UV;
Geospatial
可以用来保存地理位置,并作位置距离计算或者根据半径计算位置等。有没有想过用Redis来实现附近的人?或者计算最优地图路径?
pub/sub
功能是订阅发布功能,可以用作简单的消息队列。
Pipeline
可以批量执行一组指令,一次性返回全部结果,可以减少频繁的请求应答。
Lua
Redis 支持提交 Lua 脚本来执行一系列的功能, 利用他的原子性。
事务
最后一个功能是事务,但 Redis 提供的不是严格的事务,Redis 只保证串行执行命令,并且能保证全部执行,但是执行命令失败时并不会回滚,而是会继续执行下去。
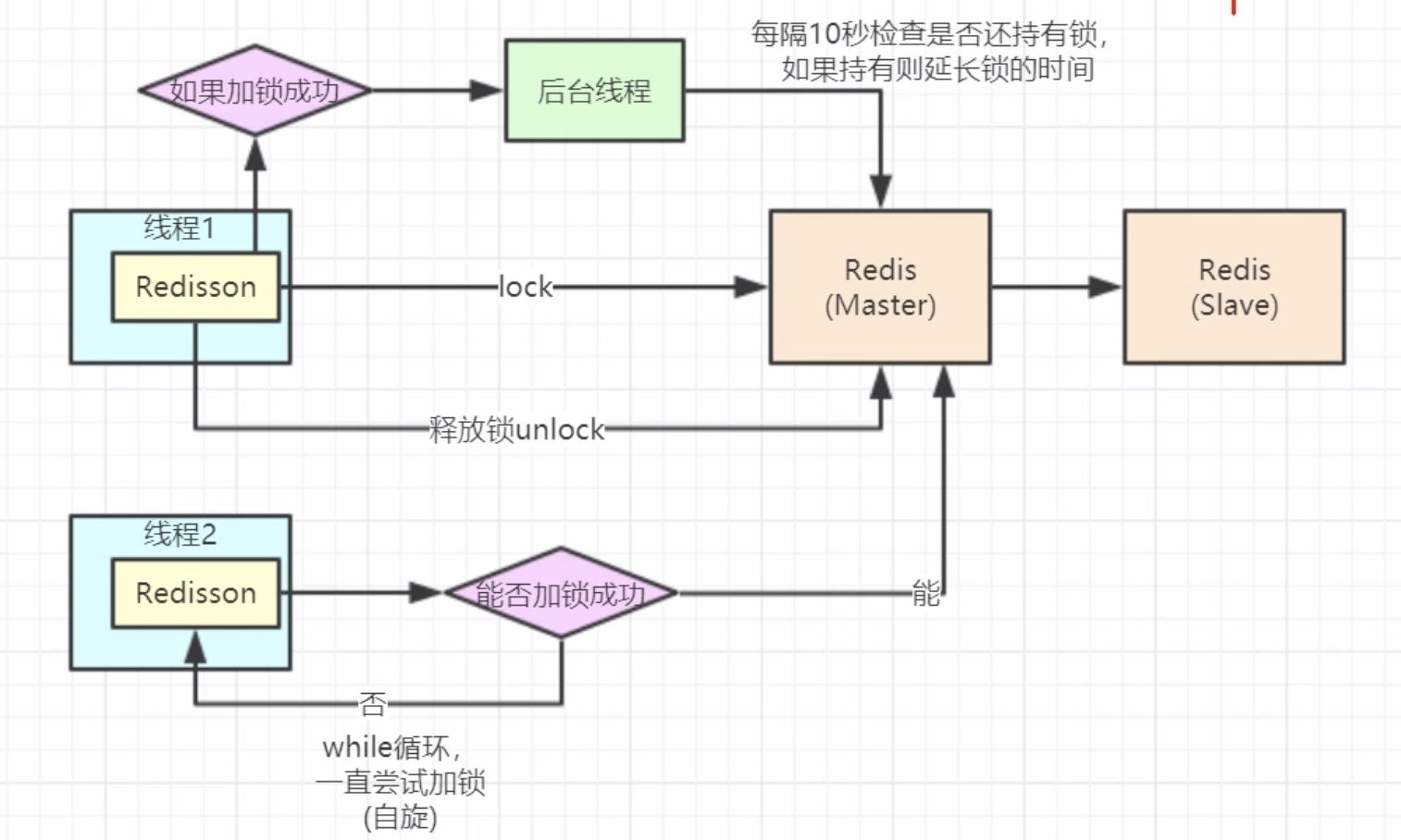
Redisson实现分布式锁
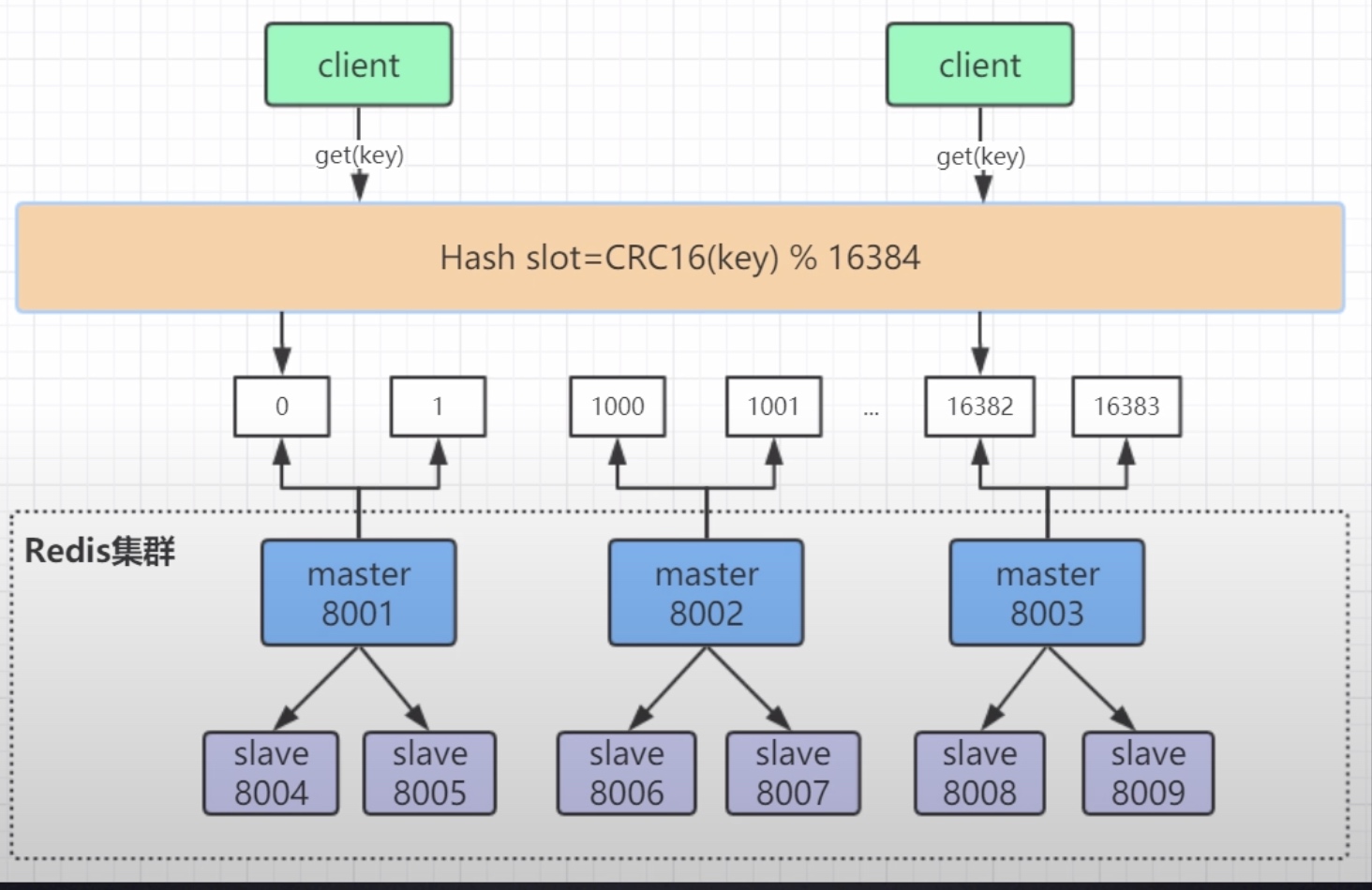
Redis集群
参考
[1]《吊打面试官》系列-Redis基础
[2]《吊打面试官》系列-缓存雪崩、击穿、穿透
[3]《吊打面试官》系列-Redis哨兵、持久化、主从、手撕LRU
[4]《吊打面试官》系列-Redis终章凛冬将至、FPX新王登基
[5]《吊打面试官》系列-秒杀系统设计