重识Count()
COUNT(列名)、COUNT(常量)和COUNT(*)之间区别
前面我们提到过 COUNT(expr) 用于做行数统计,统计的是expr不为NULL的行数,那么 COUNT(列名)、 COUNT(常量) 和 COUNT(*) 这三种语法中,expr分别是列名、 常量 和 *。
那么列名、 常量 和 * 这三个条件中,常量 是一个固定值,肯定不为NULL。* 可以理解为查询整行,所以肯定也不为NULL,那么就只有列名的查询结果有可能是NULL了。
所以, COUNT(常量) 和 COUNT(*)表示的是直接查询符合条件的数据库表的行数。而COUNT(列名)表示的是查询符合条件的列的值不为NULL的行数。
除了查询得到结果集有区别之外,COUNT(*)相比COUNT(常量) 和 COUNT(列名)来讲,COUNT(*)是SQL92定义的标准统计行数的语法,因为他是标准语法,所以MySQL数据库对他进行过很多优化。
COUNT(*)的优化
MyISAM和InnoDB有很多区别,其中有一个关键的区别和我们接下来要介绍的COUNT(*)有关,那就是:
- MyISAM不支持事务,MyISAM中的锁是表级锁;
- 而InnoDB支持事务,并且支持行级锁;
因为MyISAM的锁是表级锁,同一张表上面的操作需要串行进行,所以,MyISAM做了一个简单的优化:
它可以把表的总行数单独记录下来,如果从一张表中使用
COUNT(*)进行查询的时候,可以直接返回这个记录下来的数值就可以了,当然,前提是不能有where条件。
MyISAM之所以可以把表中的总行数记录下来供COUNT(*)查询使用,那是因为MyISAM数据库是表级锁,不会有并发的数据库行数修改,所以查询得到的行数是准确的。
但是,对于InnoDB来说,就不能做这种缓存操作了,因为InnoDB支持事务,其中大部分操作都是行级锁,所以可能表的行数可能会被并发修改,那么缓存记录下来的总行数就不准确了。
在InnoDB中,使用COUNT(*)查询行数的时候,不可避免的要进行扫表了,那么,就可以在扫表过程中下功夫来优化效率了。
从MySQL 8.0.13开始,针对InnoDB的 SELECT COUNT(*) FROM tbl_name 语句,确实在扫表的过程中做了一些优化。前提是查询语句中不包含WHERE或GROUP BY等条件。
COUNT(*)的目的只是为了统计总行数,所以,他根本不关心自己查到的具体值,所以,他如果能够在扫表的过程中,选择一个成本较低的索引进行的话,那就可以大大节省时间。
我们知道,InnoDB中索引分为聚簇索引(主键索引)和非聚簇索引(非主键索引),聚簇索引的叶子节点中保存的是整行记录,而非聚簇索引的叶子节点中保存的是该行记录的主键的值。
相比之下,非聚簇索引要比聚簇索引小很多,所以MySQL会优先选择最小的非聚簇索引来扫表。所以,当我们建表的时候,除了主键索引以外,创建一个非主键索引还是有必要的。
至此,我们介绍完了MySQL数据库对于COUNT(*)的优化,这些优化的前提都是查询语句中不包含WHERE以及GROUP BY条件。
COUNT(*)和COUNT(1)
看下MySQL官方文档是怎么说的:
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
画重点:same way , no performance difference。所以,对于COUNT(1)和COUNT(*),MySQL的优化是完全一样的,根本不存在谁比谁快!
建议使用COUNT(*)!因为这个是SQL92定义的标准统计行数的语法。
COUNT(字段)
最后,就是我们一直还没提到的COUNT(字段),他的查询就比较简单粗暴了,就是进行全表扫描,然后判断指定字段的值是不是为NULL,不为NULL则累加。
相比COUNT(*),COUNT(字段)多了一个步骤就是判断所查询的字段是否为NULL,所以他的性能要比COUNT(*)慢。
事务及原理
事务的 ACID 属性
原子性(Atomicity):作为逻辑工作单元,一个事务里的所有操作的执行,要么全部成功,要么全部失败。
一致性(Consistency):数据库从一个一致性状态变换到另外一个一致性状态,数据库的完整性不会受到破坏。
隔离性(Isolation):通常来说,一个事务所做的修改在最终提交前,对其他事务是不可见的。为什么是通常来说,为了提高事务的并发引出不同的隔离级别,具体参考下一章节。
持久性(Durability):一旦事务提交,则其所做的修改就会永久保存到数据库中,即使系统故障,修改的数据也不会丢失。
事务的隔离级别
为了尽可能的高并发,事务的隔离性被分为四个级别:读未提交、读已提交、可重复读和串行化。用户可以根据需要选择不同的级别。
未提交读(READ UNCOMMITTED):一个事务还未提交,它的变更就能被别的事务看到。
例:事务 A 可以读到事务 B 修改的但还未提交的数据,会导致脏读(可能事务 B 在提交后失败了,事务 A 读到的数据是脏的)。
提交读(READ COMMITTED):一个事务提交后,它的变更才能被其他事务看到。大多数据库系统的默认级别,但 Mysql 不是。
例:事务 A 只能读到事务 B 修改并提交后的数据,会导致不可重复读(事务 A 中执行两次查询,一次在事务 B 提交过程中,一次在事务 B 提交之后,会导致两次读取的结果不一致)。
可重复读(REPEATABLE READ):未提交的事务的变更不能被其他事务看到,同时一次事务过程中多次读取同样记录的结果是一致的。
例:事务 A 在执行过程中多次获取某范围内的记录,事务 B 提交后在此范围内插入或者删除 N条记录,事务 A 执行过程中多次范围读会存在不一致,即幻读(Mysql 的默认级别,InnoDB 通过 MVVC 解决了幻读的问题)。
可串行化(SERIALIZABLE):当两个事务间存在读写冲突时,数据库通过加锁强制事务串行执行,解决了前面所说的所有问题(脏读、不可重复读、幻读)。是最高隔离的隔离级别。
用表格可以更清晰的描述四种隔离级别的定义和可能存在的问题:
以上是对四种隔离级别的定义和初步认识,看《十分钟搞懂MySQL四种事务隔离级别》这篇文章可以彻底弄清楚他们之间的区别。
分库分表
概念
分表 - 解决单表数据过大
比如你单表都几千万数据了,你确定你能扛住么?绝对不行,单表数据量太大,会极大影响你的 sql 执行的性能,到了后面你的 sql 可能就跑的很慢了。一般来说,就以我的经验来看,单表到几百万的时候,性能就会相对差一些了,你就得分表了。分表就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在 200 万以内。
分库 - 解决单库并发压力太大
一个库一般我们经验而言,最多支撑到并发 2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。分库分表前 分库分表后 并发支撑情况 MySQL 单机部署,扛不住高并发 MySQL从单机到多机,能承受的并发增加了多倍 磁盘使用情况 MySQL 单机磁盘容量几乎撑满 拆分为多个库,数据库服务器磁盘使用率大大降低 SQL 执行性能 单表数据量太大,SQL 越跑越慢 单表数据量减少,SQL 执行效率明显提升
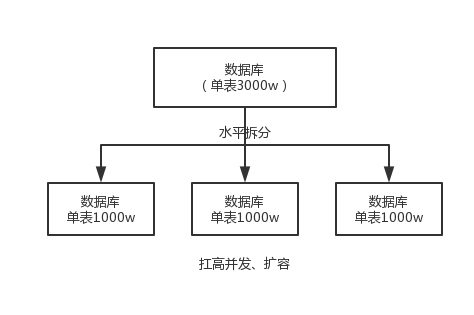
水平拆分
水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来扛更高的并发,还有就是用多个库的存储容量来进行扩容。
垂直拆分
垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
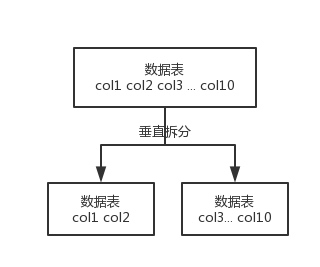
这个其实挺常见的,不一定我说,大家很多同学可能自己都做过,把一个大表拆开,订单表、订单支付表、订单商品表。
拆表不拆库
还有表层面的拆分,就是分表,将一个表变成 N 个表,就是让每个表的数据量控制在一定范围内,保证 SQL 的性能。否则单表数据量越大,SQL 性能就越差。一般是 200 万行左右,不要太多,但是也得看具体你怎么操作,也可能是 500 万,或者是 100 万。你的SQL越复杂,就最好让单表行数越少。
分库分表策略
垂直拆分,你可以在表层面来做,对一些字段特别多的表做一下拆分;
水平拆分,你可以说是并发承载不了,或者是数据量太大,容量承载不了,你给拆了,按什么字段来拆,你自己想好;
分表,你考虑一下,你如果哪怕是拆到每个库里去,并发和容量都 ok 了,但是每个库的表还是太大了,那么你就分表不分库,将这个表分开,保证每个表的数据量并不是很大。
而且这儿还有两种分库分表的方式:
按照 range 来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用。
优点: 扩容的时候很简单,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了
缺点:很容易产生热点问题,大量的流量都打在最新的数据上。实际生产用 range,要看场景;
按照某个字段 hash 一下均匀分散,这个较为常用。
优点:可以平均分配每个库的数据量和请求压力;
缺点:扩容起来比较麻烦,会有一个数据迁移的过程,之前的数据需要重新计算 hash 值重新分配到不同的库或表。
分库分表中间件
比较常见的包括:
Cobar
阿里 b2b 团队开发和开源的,属于 proxy 层方案,就是介于应用服务器和数据库服务器之间。应用程序通过 JDBC 驱动访问 Cobar 集群,Cobar 根据 SQL 和分库规则对 SQL 做分解,然后分发到 MySQL 集群不同的数据库实例上执行。早些年还可以用,但是最近几年都没更新了,基本没啥人用,差不多算是被抛弃的状态吧。而且不支持读写分离、存储过程、跨库 join 和分页等操作。
TDDL
淘宝团队开发的,属于 client 层方案。支持基本的 crud 语法和读写分离,但不支持 join、多表查询等语法。目前使用的也不多,因为还依赖淘宝的 diamond 配置管理系统。
Atlas
360 开源的,属于 proxy 层方案,以前是有一些公司在用的,但是确实有一个很大的问题就是社区最新的维护都在 5 年前了。所以,现在用的公司基本也很少了。
Sharding-jdbc
当当开源的,属于 client 层方案,目前已经更名为 ShardingSphere(后文所提到的 Sharding-jdbc,等同于 ShardingSphere)。确实之前用的还比较多一些,因为 SQL 语法支持也比较多,没有太多限制,而且截至 2019.4,已经推出到了 4.0.0-RC1 版本,支持分库分表、读写分离、分布式 id 生成、柔性事务(最大努力送达型事务、TCC 事务)。而且确实之前使用的公司会比较多一些(这个在官网有登记使用的公司,可以看到从 2017 年一直到现在,是有不少公司在用的),目前社区也还一直在开发和维护,还算是比较活跃,个人认为算是一个现在也可以选择的方案。
Mycat
基于 Cobar 改造的,属于 proxy 层方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用了。但是确实相比于 Sharding jdbc 来说,年轻一些,经历的锤炼少一些。
总结
综上,现在其实建议考量的,就是 Sharding-jdbc 和 Mycat,这两个都可以去考虑使用。
Sharding-jdbc
优点: 这种 client 层方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,建议中小型公司选用;
缺点: 如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合 Sharding-jdbc 的依赖;
Mycat
优点: 对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞定就行;
优点: 这种 proxy 层方案的缺点在于需要部署,自己运维一套中间件,运维成本高,最好是专门弄个人来研究和维护 Mycat,然后大量项目直接透明使用即;
Mysql主从复制
读写分离
其实很简单,就是基于主从复制架构,简单来说,就搞一个主库,挂多个从库,然后我们就单单只是写主库,然后主库会自动把数据给同步到从库上去。
主从复制原理
主库将变更写入 binlog 日志,然后从库连接到主库之后,从库有一个 IO 线程,将主库的 binlog 日志拷贝到自己本地,写入一个 relay 中继日志中。接着从库中有一个 SQL 线程会从中继日志读取 binlog,然后执行 binlog 日志中的内容,也就是在自己本地再次执行一遍 SQL,这样就可以保证自己跟主库的数据是一样的。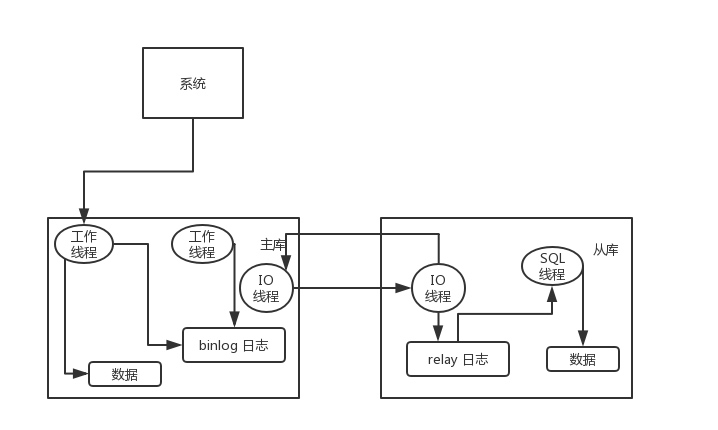
这里有一个非常重要的一点,就是从库同步主库数据的过程是串行化的,也就是说主库上并行的操作,在从库上会串行执行。所以这就是一个非常重要的点了,由于从库从主库拷贝日志以及串行执行 SQL 的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
而且这里还有另外一个问题,就是如果主库突然宕机,然后恰好数据还没同步到从库,那么有些数据可能在从库上是没有的,有些数据可能就丢失了。
所以 MySQL 实际上在这一块有两个机制,一个是半同步复制,用来解决主库数据丢失问题;一个是并行复制,用来解决主从同步延时问题。
半同步复制
也叫 semi-sync 复制,指的就是主库写入 binlog 日志之后,强制立即将数据同步到从库,从库将日志写入自己本地的 relay log 之后,接着会返回一个 ack 给主库,主库接收到至少一个从库的 ack 之后才会认为写操作完成了;并行复制
从库开启多个线程,并行读取 relay log 中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。
主从同步延时问题
一般来说,如果主从延迟较为严重,有以下解决方案:
分库,将一个主库拆分为多个主库,每个主库的写并发就减少了几倍,此时主从延迟可以忽略不计;
打开MySQL支持的并行复制,多个库并行复制。如果说某个库的写入并发就是特别高,单库写并发达到了 2000/s,并行复制还是没意义;
重写代码,写代码的同学,要慎重,插入数据时立马查询可能查不到;
如果确实是存在必须先插入,立马要求就查询到,然后立马就要反过来执行一些操作,对这个查询设置直连主库。不推荐这种方法,如果这么做,读写分离的意义就丧失了。