ThreadLocal的作用
ThreadLocal的作用是提供线程内的局部变量,说白了,就是在各线程内部创建一个变量的副本,相比于使用各种锁机制访问变量,ThreadLocal的思想就是用空间换时间,使各线程都能访问属于自己这一份的变量副本,变量值不互相干扰,减少同一个线程内的多个函数或者组件之间一些公共变量传递的复杂度。
ThreadLocal特性及使用场景
- 1、方便同一个线程使用某一对象,避免不必要的参数传递;
- 2、线程间数据隔离(每个线程在自己线程里使用自己的局部变量,各线程间的ThreadLocal对象互不影响);
- 3、获取数据库连接、Session、关联ID(比如日志的uniqueID,方便串起多个日志);
ThreadLocal应注意
- 1、ThreadLocal并未解决多线程访问共享对象的问题;
- 2、ThreadLocal并不是每个线程拷贝一个对象,而是直接new(新建)一个;
- 3、如果ThreadLocal.set()的对象是多线程共享的,那么还是涉及并发问题。
图解TreadLocal
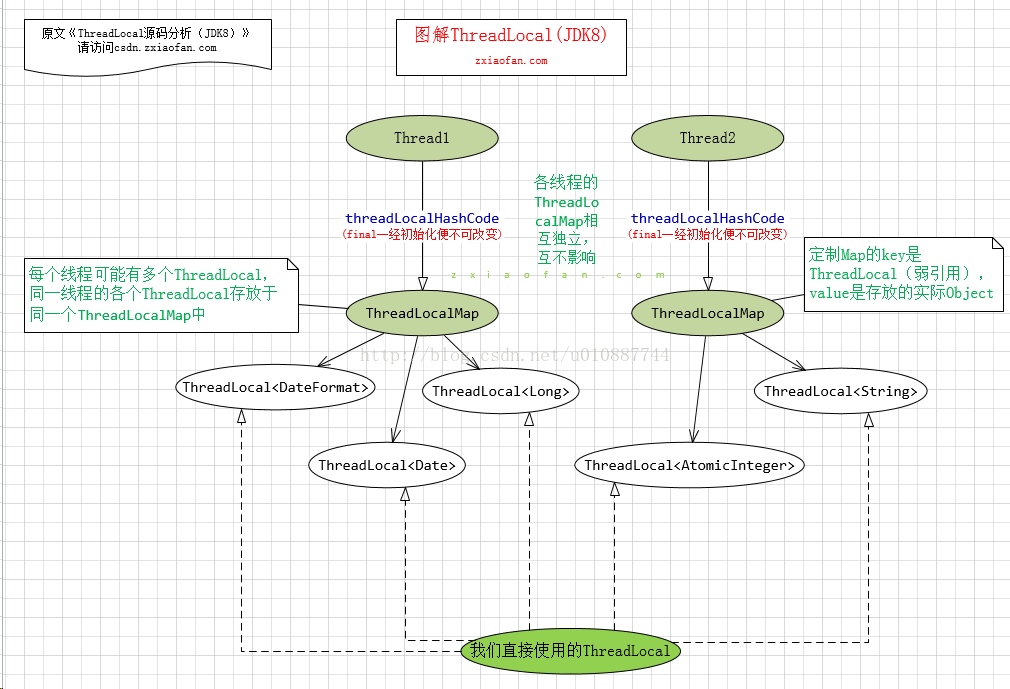
每个线程可能有多个ThreadLocal,同一线程的各个ThreadLocal存放于同一个ThreadLocalMap中。
图解ThreadLocal(JDK8).vsdx原图下载地址:https://github.com/zxiaofan/JDK-Study/tree/master/src/java1/lang/threadLocal
内部类
ThreadLocalMap
1 | static class ThreadLocalMap { |
ThreadLocalMap是定制的hashMap,仅用于维护当前线程的本地变量值。仅ThreadLocal类对其有操作权限,是Thread的私有属性。为避免占用空间较大或生命周期较长的数据常驻于内存引发一系列问题,hash table的key是弱引用WeakReferences。当空间不足时,会清理未被引用的entry。这时Entry里的key为null了,那么直到线程结束前,Entry中的value都是无法回收的,这里可能产生内存泄露。
SuppliedThreadLocal
1 | static final class SuppliedThreadLocal<T> extends ThreadLocal<T> { |
SuppliedThreadLocal是JDK8新增的内部类,只是扩展了ThreadLocal的初始化值的方法而已,允许使用JDK8新增的Lambda表达式赋值。需要注意的是,函数式接口Supplier不允许为null。
初始化
1 | public class ThreadLocal<T> { |
ThreadLocal类变量有3个,其中2个是静态变量(包括一个常量),实际作为作为ThreadLocal实例的变量只有threadLocalHashCode这1个,而且已经初始化就不可变了。
其中withInitial()方法使用示例:
1 | public void jdk8Test(){ |
源码分析
get方法
1 | public T get() { |
直接看代码,可以分析主要有以下几步:
- 获取当前的Thread对象,通过getMap获取Thread内的ThreadLocalMap
- 如果map已经存在,以当前的ThreadLocal为键,获取Entry对象,并从从Entry中取出值
- 否则,调用setInitialValue进行初始化。
getMap
1 | ThreadLocalMap getMap(Thread t) { |
getMap很简单,就是返回线程中ThreadLocalMap,跳到Thread源码里看,ThreadLocalMap是这么定义的:
1 | ThreadLocal.ThreadLocalMap threadLocals = null; |
所以ThreadLocalMap还是定义在ThreadLocal里面的,我们前面已经说过ThreadLocalMap中的Entry定义,下面为了先介绍ThreadLocalMap的定义我们把setInitialValue放在前面说。
setInitialValue
1 | private T setInitialValue() { |
setInititialValue在Map不存在的时候调用。
首先是调用initialValue生成一个初始的value值,深入initialValue函数,我们可知它就是返回一个null,如果创建ThreadLocal时调用withInitial() 方法指定了初始方法,则返回自定义值;
还是在get()一下Map,如果map存在,则直接map.set(), 这个函数会放在后文说;
- 如果map不存在,则会调用createMap()创建ThreadLocalMap。
createMap
1 | void createMap(Thread t, T firstValue) { |
比较简单,就是调用了ThreadLocalMap内部类的构造函数而已。
map.getEntry
1 | private Entry getEntry(ThreadLocal<?> key) { |
- 首先是计算索引位置i,通过计算key的hash%(table.length-1)得出;
- 根据获取Entry,如果Entry存在且Entry的key恰巧等于ThreadLocal,那么直接返回Entry对象;
- 否则,也就是在此位置上找不到对应的Entry,那么就调用getEntryAfterMiss。
getEntryAfterMiss
1 | private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { |
这个方法我们还得结合上一步看,上一步是因为不满足
1 | e != null && e.get() == key |
才沦落到调用getEntryAfterMiss的,所以:
首先e如果为null的话,证明不存在value, 那么getEntryAfterMiss还是直接返回null的
如果是不满足e.get() == key,那么进入while循环,这里是不断循环,如果e一直不为空,那么就调用nextIndex,不断递增i,在此过程中一直会做两个判断:
如果 k == key, 那么代表找到了这个所需要的Entry,直接返回;
如果 k == null,那么证明这个Entry中key已经为null, 那么这个Entry就是一个过期对象,这里调用expungeStaleEntry清理该Entry。这里解答了前面留下的一个坑,即ThreadLocal Ref销毁时,ThreadLocal实例由于只有Entry中的一条弱引用指着,那么就会被GC掉,Entry的key没了,value可能会内存泄露的,其实在每一个get,set操作时都会不断清理掉这种key为null的Entry的。
为什么循环查找?
这里你可以直接跳到下面的set方法,主要是因为处理哈希冲突的方法,我们都知道HashMap采用拉链法处理哈希冲突,即在一个位置已经有元素了,就采用链表把冲突的元素链接在该元素后面,而ThreadLocal采用的是开放地址法,即有冲突后,把要插入的元素放在要插入的位置后面为null的地方
具体关于这两种方法的区别可以参考:解决哈希(HASH)冲突的主要方法。
所以上面的循环就是因为我们在第一次计算出来的i位置不一定存在key与我们想查找的key恰好相等的Entry,所以只能不断在后面循环,来查找是不是被插到后面了,直到找到为null的元素,因为若是插入也是到null为止的。
expungeStaleEntry
1 | private int expungeStaleEntry(int staleSlot) { |
看上面这段代码主要有两部分:
(1) 这段主要是将i位置上的Entry的value设为null,Entry的引用也设为null,那么系统GC的时候自然会清理掉这块内存;
(2) 这段就是扫描位置staleSlot之后,null之前的Entry数组,清除每一个key为null的Entry,同时若是key不为空,做rehash,调整其位置。
为什么要做rehash呢?
因为我们在清理的过程中会把某个值设为null,那么这个值后面的区域如果之前是连着前面的,那么下次循环查找时,就会只查到null为止。
举个例子就是:
…, <key1(hash1), value1>, <key2(hash1), value2>,…
即key1和key2的hash值相同, 此时,若插入
<key3(hash2), value3>
其hash计算的目标位置被
<key2(hash1), value2>
占了,于是往后寻找可用位置,hash表可能变为:
…, <key1(hash1), value1>, <key2(hash1), value2>, <key3(hash2), value3>, …
此时,若
<key2(hash1), value2>
被清理,显然
<key3(hash2), value3>
应该往前移(即通过rehash调整位置),否则若以key3查找hash表,将会找不到key3。
set方法
我们在get方法的循环查找那里也大概描述了set方法的思想,即开放地址法,下面看具体代码:
1 | public void set(T value) { |
首先也是获取当前线程,根据线程获取到ThreadLocalMap,若是有ThreadLocalMap,则调用
1 | map.set(ThreadLocal<?> key, Object value) |
若是没有则调用createMap创建。
map.set
1 | private void set(ThreadLocal<?> key, Object value) { |
看上面这段代码:
首先还是根据key计算出位置i,然后查找i位置上的Entry,
若是Entry已经存在并且key等于传入的key,那么这时候直接给这个Entry赋新的value值。
若是Entry (e != null) 存在,但是key为null,则调用replaceStaleEntry来更换这个key为空的Entry
不断循环检测,直到遇到为null的地方,这时候要是还没在循环过程中return,那么就在这个null的位置新建一个Entry,并且插入,同时size增加1。
最后调用cleanSomeSlots,这个函数就不细说了,你只要知道内部还是调用了上面提到的expungeStaleEntry函数清理key为null的Entry就行了,最后返回是否清理了Entry,接下来再判断 sz>thresgold ,这里就是判断是否达到了rehash的条件,达到的话就会调用rehash函数。
上面这段代码有两个函数还需要分析下,首先是:
replaceStaleEntry
1 | private void replaceStaleEntry(ThreadLocal<?> key, Object value, |
首先我们回想上一步是因为这个位置的Entry的key为null才调用replaceStaleEntry。
第1个for循环:我们向前找到key为null的位置,记录为slotToExpunge,这里是为了后面的清理过程,可以不关注了;
第2个for循环:我们从staleSlot起到下一个null为止,若是找到key和传入key相等的Entry,就给这个Entry赋新的value值,并且把它和staleSlot位置的Entry交换,然后调用CleanSomeSlots清理key为null的Entry。
若是一直没有key和传入key相等的Entry,那么就在staleSlot处新建一个Entry。函数最后再清理一遍空key的Entry。
说完replaceStaleEntry,还有个重要的函数是rehash以及rehash的条件:
首先是sz > threshold时调用rehash
rehash
1 | private void rehash() { |
清理完空key的Entry后,如果size大于3/4的threshold,则调用resize函数:
resize
1 | private void resize() { |
由源码我们可知每次扩容大小扩展为原来的2倍,然后再一个for循环里,清除空key的Entry,同时重新计算key不为空的Entry的hash值,把它们放到正确的位置上,再更新ThreadLocalMap的所有属性。
remove
最后一个需要探究的就是remove函数,它用于在map中移除一个不用的Entry。也是先计算出hash值,若是第一次没有命中,就循环直到null,在此过程中也会调用expungeStaleEntry清除空key节点。代码如下:
1 | private void remove(ThreadLocal<?> key) { |
使用ThreadLocal的最佳实践
我们发现无论是set,get还是remove方法,过程中key为null的Entry都会被擦除,那么Entry内的value也就没有强引用链,GC时就会被回收。那么怎么会存在内存泄露呢?但是以上的思路是假设你调用get或者set方法了,很多时候我们都没有调用过,所以最佳实践就是:
- 使用者需要手动调用remove函数,删除不再使用的ThreadLocal.
- 尽量将ThreadLocal设置成private static的,这样ThreadLocal会尽量和线程本身一起消亡。
问题与思考
(1)如果有多个ThreadLocal都对同一个线程ThreadLocalMap写数据时,可能存在hash位置冲突,导致set()和get()效率显著下降;
(2)ThreadLocal不能读取父线程的ThradLocalMap内容,需要使用InheritableThreadLocal;