本文从源码层面去解读下java线程池的实现思想和代码。
总览
先看一张java线程池的继承关系图:
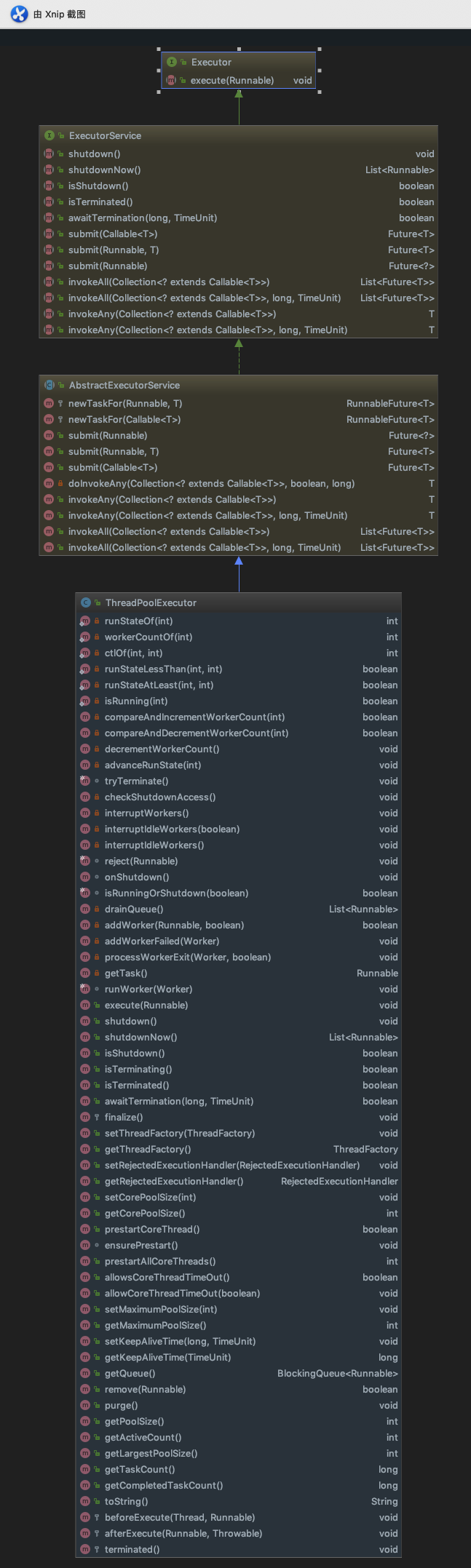
简单介绍下:
Executor 位于最顶层,也是最简单的,只有一个 execute(Runnable runnable) 接口方法定义
ExecutorService 也是接口,在 Executor 接口的基础上添加了很多的接口方法,很多时候我们使用这个接口就够了
AbstractExecutorService,这是抽象类,这里实现了非常有用的一些方法供子类直接使用,例如: invokeAll()、 invokeAny()
ThreadPoolExecutor 类,这个类才是真正的线程池实现,提供了非常丰富的功能。
从图中的方法可以看到,还涉及到一些其他类:
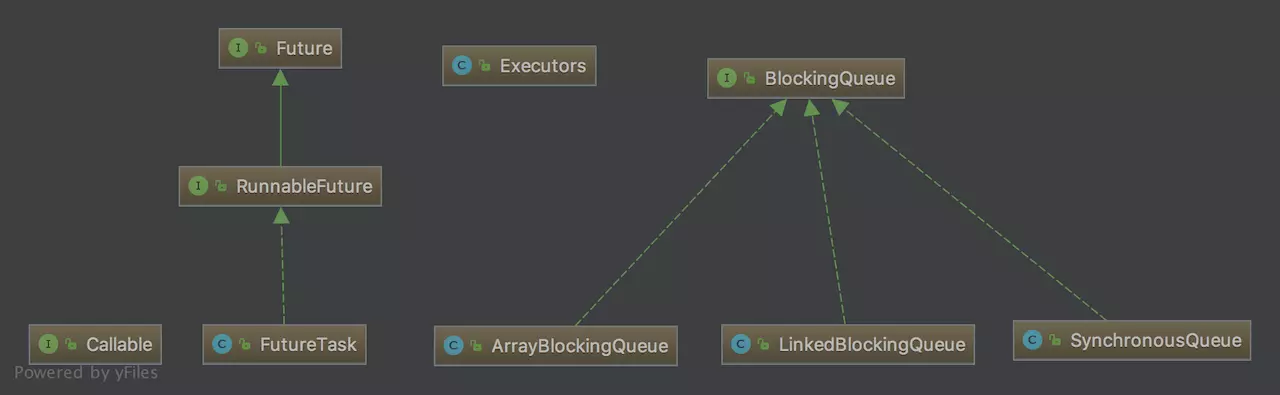
其中:
Executors类
这个是工具类,里面的方法都是静态方法,如以下我们最常用的用于生成 ThreadPoolExecutor 的实例的一些方法:1
2
3
4
5
6
7
8
9
10
11
12public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}Future接口
由于线程池支持获取线程执行的结果,所以,引入了 Future 接口,RunnableFuture 继承自此接口,然后我们最需要关心的就是它的实现类 FutureTask。FutureTask类
在线程池的使用过程中,我们是往线程池提交任务(task),我们提交的每个任务是实现了 Runnable 接口的,其实就是先将 Runnable 的任务包装成 FutureTask,然后再提交到线程池。它首先是一个任务(Task),然后具有 Future 接口的语义,即可以在将来(Future)得到执行的结果。BlockingQueue
如果线程数达到 corePoolSize,我们的每个任务会提交到等待队列中,等待线程池中的线程来取任务并执行。这里的 BlockingQueue 通常我们使用其实现类 LinkedBlockingQueue、ArrayBlockingQueue 和 SynchronousQueue,每个实现类都有不同的特征.
Executor接口
1 | /* |
可以看到 Executor 接口非常简单,就一个 void execute(Runnable command) 方法,代表提交一个任务。为了理解 java 线程池的整个设计方案,我会按照 Doug Lea 的设计思路来多说一些相关的东西。
我们经常这样启动一个线程:
1 | new Thread(new Runnable(){ |
用了线程池 Executor 后就可以像下面这么使用:
1 | Executor executor = anExecutor; |
如果我们希望线程池同步执行每一个任务,我们可以这么实现这个接口:
1 | class DirectExecutor implements Executor { |
如果我们希望每个任务提交进来后,直接启动一个新的线程来执行这个任务,我们可以这么实现:
1 | class ThreadPerTaskExecutor implements Executor { |
我们再来看下怎么组合两个 Executor 来使用,下面这个实现是将所有的任务都加到一个 queue 中,然后从 queue 中取任务,交给真正的执行器执行,这里采用 synchronized 进行并发控制:
1 | class SerialExecutor implements Executor { |
Executor 这个接口只有提交任务的功能,太简单了,我们想要更丰富的功能,比如我们想知道执行结果、我们想知道当前线程池有多少个线程活着、已经完成了多少任务等等,这些都是这个接口的不足的地方。接下来我们要介绍的是继承自 Executor 接口的 ExecutorService 接口,这个接口提供了比较丰富的功能,也是我们最常使用到的接口。
ExecutorService
简单初略地来看一下这个接口中都有哪些方法:
1 | 简单初略地来看一下这个接口中都有哪些方法: |
这些方法都很好理解,一个简单的线程池主要就是这些功能,能提交任务,能获取结果,能关闭线程池,这也是为什么我们经常用这个接口的原因。
FutureTask
在继续往下层介绍 ExecutorService 的实现类之前,我们先来说说相关的类 FutureTask。
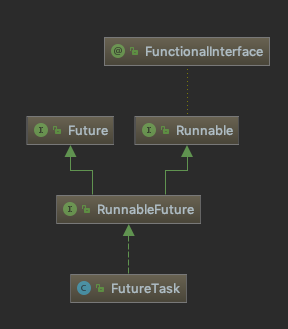
FutureTask 通过 RunnableFuture 间接实现了 Runnable 接口,所以每个 Runnable 通常都先包装成 FutureTask,然后调用 executor.execute(Runnable command) 将其提交给线程池.
Runnable 的 void run() 方法是没有返回值的,所以,通常,如果我们需要的话,会在 submit 中指定第二个参数作为返回值:
1 | <T> Future<T> submit(Runnable task, T result); |
其实到时候会通过这两个参数,将其包装成 Callable。
Callable 也是因为线程池的需要,所以才有了这个接口。它和 Runnable 的区别在于 run() 没有返回值,而 Callable 的 call() 方法有返回值,同时,如果运行出现异常,call() 方法会抛出异常。
1 | public interface Callable<V> { |
1 | public interface Runnable { |
下面,我们来看看 ExecutorService 的抽象实现 AbstractExecutorService 。
AbstractExecutorService
AbstractExecutorService 抽象类派生自 ExecutorService 接口,然后在其基础上实现了几个实用的方法,这些方法提供给子类进行调用。
- invokeAny方法:
- invokeAll方法:
- newTaskFor方法: 用于将任务包装成 FutureTask
定义于最上层接口 Executor中的 void execute(Runnable command) 由于不需要获取结果,不会进行 FutureTask 的包装。
需要获取结果(FutureTask),用 submit 方法,不需要获取结果,可以用 execute 方法。
下面重点讲解下newTaskFor和invokeAny、invokeAll方法源码。
newTaskFor && submit
1 | public abstract class AbstractExecutorService implements ExecutorService { |
invokeAny
1 | /** |
invokeAll
1 | /** |
到这里,我们发现,这个抽象类包装了一些基本的方法,可是像 submit、invokeAny、invokeAll 等方法,它们都没有真正开启线程来执行任务,它们都只是在方法内部调用了 execute 方法,所以最重要的 execute(Runnable runnable) 方法还没出现,需要等具体执行器来实现这个最重要的部分,这里我们要说的就是 ThreadPoolExecutor 类了。
ThreadPoolExecutor
ThreadPoolExecutor 是 JDK 中的线程池实现,这个类实现了一个线程池需要的各个方法,它实现了任务提交、线程管理、监控等等方法。
构造函数
Executors 这个工具类来快速构造一个线程池,对于初学者而言,这种工具类是很有用的,开发者不需要关注太多的细节,只要知道自己需要一个线程池,仅仅提供必需的参数就可以了,其他参数都采用作者提供的默认值。其调用的就是构造函数。
1 | /** |
关键变量
除了构造函数以外,还需要重点关注下几个重要的属性和函数。
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
看了这几种状态的介绍,读者大体也可以猜到十之八九的状态转换了,各个状态的转换过程有以下几种:
1 | RUNNING -> SHUTDOWN:当调用了 shutdown() 后,会发生这个状态转换,这也是最重要的 |
上面的几个记住核心的就可以了,尤其第一个和第二个。
另外,我们还要看看一个内部类 Worker,因为 Doug Lea 把线程池中的线程包装成了一个个 Worker,翻译成工人,就是线程池中做任务的线程。所以到这里,我们知道任务是 Runnable(内部叫 task 或 command),线程是 Worker。
1 | /** |
excute()
有了上面的这些基础后,我们终于可以看看 ThreadPoolExecutor 的 execute 方法了,前面源码分析的时候也说了,各种方法都最终依赖于 execute 方法. 首先分析下execute主要工作流程:
- (1)任务submit后先通过newTaskFor()封装成可返回结果的FutureTask;
- (2)调用execute方法执行;
- (3)execute方法在当前线程数(WC)小于coreSize时,直接创建新线程处理;
- (4)如果创建新线程失败,尝试加入任务队列,若此时线程池已经处于非Running状态,则不做处理;
- (5)成功加入任务队列后需要再次确认线程池状态(有可能在加入队列操作的过程中,线程池被shutdown了),如果此时线程池非Running,则移除该任务,执行拒绝策略;如果状态正常,则判断WC==0,如果等于0说明线程池中没有线程了,则创建一个新线程添加到pool中;
- (6)如果加入队列失败或者当前状态非Running, 则尝试创建新线程来处理该任务,如果失败,则执行拒绝策略;
具体流程如下图: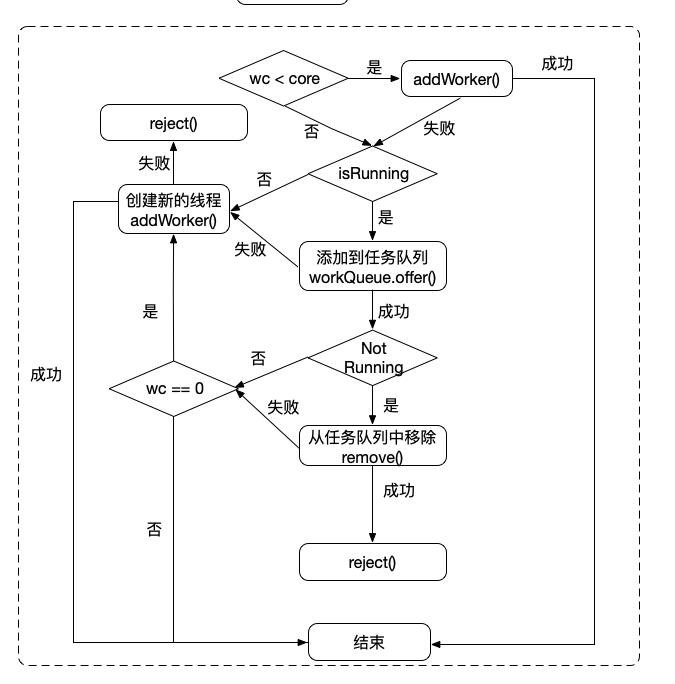
本来想用一张图表示整个流程,结果发现图还没有看源代码清晰,干脆放弃了,直接看代码吧。
1 | public void execute(Runnable command) { |
addWorker()
1 | /** |
addWorkFailed()
1 | /** |
runWorker()
回过头来,继续往下走。我们知道,worker 中的线程 start 后,其 run 方法会调用 runWorker 方法:
1 | // Worker 类的 run() 方法 |
继续往下看 runWorker 方法:
1 | /** |
processWorkerExit()
1 | /** |
getTask()
getTask() 是怎么获取任务的,这个方法写得真的很好,每一行都很简单,组合起来却所有的情况都想好了:
1 | /** |
tryTerminate()
1 | /** |
拒绝策略
ThreadPoolExecutor 中的拒绝策略。
1 | /** |
Executors
Executors它仅仅是工具类,它的所有方法都是 static 的。
FixedThreadPoole
生成一个固定大小的线程池:
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
最大线程数设置为与核心线程数相等,此时 keepAliveTime 设置为 0(因为这里它是没用的,即使不为 0 也不会执行 corePoolSize 内的线程),任务队列采用 LinkedBlockingQueue,无界队列。
过程分析:刚开始,每提交一个任务都创建一个 worker,当 worker 的数量达到 nThreads 后,不再创建新的线程,而是把任务提交到 LinkedBlockingQueue 中,而且之后线程数始终为 nThreads。
SingleThreadExecutor
生成只有一个线程的固定线程池,这个更简单,和上面的一样,只要设置线程数为 1 就可以了:
1 | public static ExecutorService newSingleThreadExecutor() { |
newCachedThreadPool
生成一个需要的时候就创建新的线程,同时可以复用之前创建的线程(如果这个线程当前没有任务)的线程池:
1 | public static ExecutorService newCachedThreadPool() { |
过程分析:鉴于 corePoolSize 是 0,那么提交任务的时候,直接将任务提交到队列中,由于采用了 SynchronousQueue,所以如果是第一个任务提交的时候,offer 方法肯定会返回 false,因为此时没有任何 worker 对这个任务进行接收,那么将进入到最后一个分支来创建第一个 worker。之后再提交任务的话,取决于是否有空闲下来的线程对任务进行接收,如果有,会进入到第二个 if 语句块中,否则就是和第一个任务一样,进到最后的 else if 分支。
这种线程池对于任务可以比较快速地完成的情况有比较好的性能。如果线程空闲了 60 秒都没有任务,那么将关闭此线程并从线程池中移除。所以如果线程池空闲了很长时间也不会有问题,因为随着所有的线程都会被关闭,整个线程池不会占用任何的系统资源。
SynchronousQueue 是一个比较特殊的 BlockingQueue,其本身不储存任何元素,它有一个虚拟队列(或虚拟栈),不管读操作还是写操作,如果当前队列中存储的是与当前操作相同模式的线程,那么当前操作也进入队列中等待;如果是相反模式,则配对成功,从当前队列中取队头节点。具体的信息,可以看我的另一篇关于 BlockingQueue 的文章。
代码
带注释完整代码: https://github.com/austin-brant/thread-pool-source-code